

はじめに
本書を選んだ背景
世間ではビッグデータブームから Deep Learning の流行した2010年代からの10年間、そして新しく登場した LLM の流行により、データ分析や機械学習を応用したシステムが一般化し身近に運用されるようになってきました。しかしこれらの分野で必要となるアプリケーションの開発~運用~更新のライフサイクルは以前のシステムとは大きく異なるものになっています。そのような中で MLOps という言葉も登場し、手探りでいろいろ試す段階から一歩進み、ある程度作るものが定型化されてきています。これまで多くのエンジニアが試して XXX をしたらうまくいった、XXX という設計はなんかやばい気がする、というノウハウをテンプレート化し再利用しやすいようにまとめたものを「デザインパターン」と呼びます。
そういったノウハウを1から自分だけでまとめ自社の社員に伝えていくには非常にコストが高いので、ベースとなる情報一通りをインプットするための書籍を探して中で見つけたのが「AIエンジニアのための機械学習システムデザインパターン(著:澁井雄介)」でした。著者を含めたチームの方々が GitHub 上に情報をまとめ公開、日々更新してくれていますが、書籍の形になっているのはそれはそれで便利なので自分でも一通り目を通しました。
本書の内容
- 機械学習システムについて: Part 1 - Chapter 1
- 概要
- 必要なもの
- パターン化
- システム実装 & アーキテクチャ例: Part 2
- 学習パイプライン・実験管理: Chapter 2
- モデルの作成 (+AP-Only me パターン)
- モデルのバージョニング
- パイプライン学習パターン・バッチ学習パターン (+AP-複雑パイプラインパターン)
- モデルのリリース: Chapter 3
- 学習環境と推論環境 (+AP-バージョニング不一致パターン)
- モデルの配布と推論器の稼働
- モデルインイメージパターン・モデルロードパターン
- モデルの配布とスケールアウト
- 推論システムをつくる: Chapter 4
- Web シングルパターン
- 同期推論パターン・非同期推論パターン・バッチ推論パターン
- 前処理・推論パターン
- 直列マイクロサービスパターン・並列マイクロサービスパターン
- 時間差推論パターン
- 推論キャッシュパターン・データキャッシュパターン
- 推論器テンプレートパターン
- Edge AI パターン
- AP-オンラインビッグサイズパターン
- AP-オールインワンパターン
- 学習パイプライン・実験管理: Chapter 2
- 品質担保: Part 3
- 機械学習システムを運用する: Chapter 5
- 推論ログパターン
- 推論監視パターン
- AP-ログなしパターン
- AP-そして誰もいなくなったパターン
- 機械学習システムの品質を維持する: Chapter 6
- 品質と運用
- 正常性評価指標
- 負荷テストパターン
- 推論サーキットブレーカーパターン
- シャドウ A/B テストパターン・オンライン A/B テストパターン
- パラメータベース推論パターン・条件分岐推論パターン
- AP-オフラインのみパターン
- End-to-End な MLOps システムの設計: Chapter 7
- 課題と手法
- 需要予測システムの例
- コンテンツ投稿サービスの例
- 機械学習システムを運用する: Chapter 5
上記のような内容が記載されています(AP はアンチパターンの略)。全体のボリュームに対してアンチパターンの記載は必要最小限の記載になっていたかなと思います。ほぼすべて Python による実装、運用プラットフォームについては Docker(+ Kubernetes)を前提に書かれていました。著者の方が動作検証を行っていたのは Linux or Mac 環境のようなので Win 環境の方は適切に読み替える必要はあるかもしれませんが、基本的に Docker が使える環境があれば大丈夫かと思います。
レビュー
良かったところ
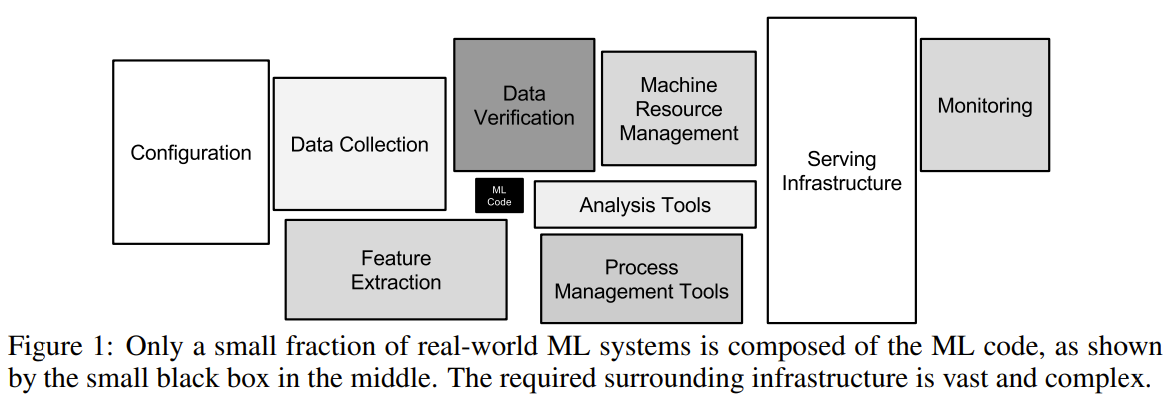
本書の1章にも記載がある有名な図です。こちらを見るとわかるように機械学習システムはメインの予測に関するコード以外の部分、関連している周辺領域が非常におおきなシステムになるため、ここにあるような内容をそれぞれ1から要所を押さえていくのはとても大変なのですが、実務でよく悩むポイントについては本書で一通りカバーできているように思いました。自分の経験と照らし合わせると特に Chapter 4 の推論システムをどう設計するのか、という点に関して詳細に記載してあるため実際に業務で誰かから相談を受けた際にまずコアとなる推論器がどのパターンに当てはまるか考え、そこから周辺部分(Chapter 2 ~ Chapter 6 にある内容)を詰めていくフローで考えればだいたい何とかなるとおもいます。
ONNX 関連については意外と現場でモデリングしている人の中では知らないままでいる方も多いのですが、こういうシステム化のためのツールに関する基礎知識を身に着けておくと間違いなく役に立つと思います。他にも高負荷が想定されるような場面で推論を行う際の並列化、キャッシュの使い方などもモデリング業務をメインに行っている方でちゃんと検討できる人は意外と少なかったので、そこまで意識して特徴量の作り方とかを工夫できるとシステム面をメインで担当するエンジニアとの共同作業が進めやすくなるはずです。
他に気になったトピックとしては、受託分析で入った現場においてオフライン評価の精度=システムの精度として再チェックされていないままシステム化され運用されているとんでもない現場がなんと1件でなく、少なくない数で起きており、実際こちらで計測したら、、、という場面を何度も見てきたので Kaggle とかのコンペではあまり意識されないこういう部分もキチンと押さえてあり良い本だと思います。
微妙だったところ
Kubernetes (k8s) 関連の話については、メルカリさんとかの規模であればメリットが出るのかもしれませんが、本書にある内容で悩むような現場だとコンテナ系の技術を使って本番環境にデプロイするのであれば、AWS ECS や GCP Cloud Run など前提で構築し、大規模になってきたタイミングで初めて AWS EKS or GCP GKE で k8s を初めて検討するのがよい気がしています。下手に k8s を導入すると本丸である MLOps 関連以外部分の負荷が高くなってしまい本末転倒になる可能性が高そうです。個人的にはしっかりした大人数のインフラチームがないまま導入すると本書にある「そして誰もいなくなったパターン」に陥りやすいパターンだと思いました。
その他
例えば Chapter 2 のモデルの管理では小さな Web ツールを自作することで解決する仕組みを提示しています。最終形としてはは実際にこのような形で管理するのがベストなのは間違いですが、「全く管理されていない」という状況からであれば Google Spreadsheet などなんでもよいのでまず記録する文化を作って、実際に必要なものを確認していくフェーズをはさんだりするほうが現場では馴染みやすかったりするので、最終系に向かうプロセス部分をどうしていくか、という部分にもいろいろ苦労はあったと思うのでそういった部分も書いて欲しかったなと思いました(そこまで求めるのは贅沢すぎる話であるとも思いますが)。
おわりに
キャリアパス的にアドホックなデータ分析をメイン業務として行っている方が、自分が行った分析内容に関連したシステムを自分で作る、もしくは誰かにお願いして作ってもらう際に道しるべになりそうな良い本でした。自社の社員にも進めたい1冊です。興味を持った方は是非読んでみてください。
参考資料
- Hidden Technical Debt in Machine Learning Systems, D. Sculley et al., Figure 1
- AIエンジニアのための機械学習システムデザインパターン
- Github: 機械学習システム デザインパターン