
はじめに
作業用のサーバを作成する理由
今回はデータ分析・AI 関連の計算を実行するための環境を作ります。計算用サーバを自宅に構築すると下記のようなメリットがあります。
- 長時間計算を実行しっぱなしにしてもメインマシンの作業に影響がない
- 気軽に環境をリセットすることが可能
- クライアント PC が非力なノート PC でも重たい計算処理が実行可能
- VPN で自宅ネットワークに接続できるようにするとカフェからでも GPU で計算可能
- ある程度使うのであればクラウド環境よりも安い
- 特に GPU サーバは利用料金がお高いので個人利用で立てっぱなしは厳しい
- シャットダウン忘れの恐怖を心配しなくてよくなる
- 自力で構築することでインフラ・運用まわりの知識がつく
インストール先環境ですが、前回の記事 「Proxmox VE 8.0 によるホームラボ構築」 で作成した PVE 環境に仮想マシンを作成してその上に構築しています。Ubuntu Server のインストール以降はほぼネイティブ環境上や一般的なクラウド環境で GPU があるマシンに導入する場合と変わらないと思います。
インストールするツールについて
下記のものをデフォルトのツールとして一式インストールする。PyTorch、PyCaret、ONNX については別途詳細を後述します。
- ソースコード管理: Git
- ダウンロード: wget
- アーカイブ関連: zip, unzip
- C, C++ ビルド関連: cmake, build-essential, libboost 系
- 線形代数演算: BLAS, LAPACK
- Python 関連
- Python本体: Python 3.9 + pip
- 開発環境: Jupyter Lab
- データ分析: scikit-learn, Numpy, Scipy, Pandas
- データモデリング: XGBoost, LightGBM, CatBoost
- AutoML: PyCaret
- データ可視化: Graphviz, Matplotlib, Japanize Matplotlib, Seaborn
- DeepLearning: PyTorch
- 進行状況管理: tqdm
- ONNX関連: skl2onnx, onnxmltools, onnxruntime-gpu
- 画像処理関連: OpenCV, Pillow
- AWS関連: Boto3
PyTorch について
DeepLearning 系モデリングを行うための Meta 社製フレームワークで、シェアは最近は Google社製の TensorFlow と同程度に見えますが、実際のところはどうなんでしょうか…?研究者は以前から PyTorch をよく利用しているため最新のモデルはこちらで実装されて出てくることが多いと思いますが、良いモデルはすぐに TensorFlow にも移植されるためどちらを選んでも大きな問題にはならないはずです。個人的な好みでこちらを利用しています。
GPU ドライバとライブラリのインストールを全部自分で行うのは依存関係の解決が非常に面倒なんですが、最近は Docker を利用するとサクッと構築可能になっており、今回は NVIDIA が出している NVIDIA Container Toolkit を組み合わせて GPU を利用可能な環境を構築します。
参考: PyTorch 公式
PyCaret について
機械学習を行う上でよく利用されるライブラリの scikit-learn は、実務でモデリングを行う際に前処理や各モデルに合わせた前処理を書く部分でコードの記述量が地味多いため、何らかの方法で楽をしたくなります。そのあたりの自動化を支援してくれる道具としてさまざまな AutoML 系のツールがあり PyCaret はその中でもオープンソース、かつフリーで利用できる導入しやすいツールです。筆者も以前は自分で書いていましたが、こちらに慣れた今、案件でパッとモデリングして結果を見るような場合は、まず PyCaret で状況を確認してみて、そのあと具体的な方策を考える、という流れで進めることが多いです。
PyCaret は少し前までは Python 本体とライブラリのバージョン制約が厳しく、バージョン2系は Python 3.7 や 3.8 + 古い scikit-learn のバージョンで構築する必要があったが、今年の3月にバージョン3系が正式版となり最近の Python + scikit-learn 環境でもきちんと動くようになりました。よって今回は2023年7月時点で最新の3系のものをインストールします。
参考: PyCaret 公式
ONNX について
Open Neural Network eXchange の略で、PyTorch、TensorFlow、scikit-learn などで学習済みの(主に機械学習)モデルを可搬性の高い ONNX モデル形式に変換することで、別環境で利用することが可能になります。
MLOps 文脈でシステムの開発と運用が行いやすくなるだけでなく、Python 環境でよく使われるフレームワーク以外にも、MacOSX や iPhone の CoreML、Android の NNAPI などモバイルデバイスのローカルで利用できるのでネイティブ系モバイルアプリに学習済みモデルを組み込めたり、制約条件の厳しいエッジコンピューティングで利用されるバックエンドなどでも利用可能だったりするので、より広い範囲で機械学習モデルによる予測、分類などを活用したシステムを作ることが可能になります。今後よりさまざまなデバイス上で機械学習系のツールが一般化していくなかで押さえておくべき技術のひとつです。
参考: ONNX 公式
Proxmox VE 上での仮想マシンの作成
「Proxmox VE 8.0 によるホームラボ構築」 で作成した環境上で仮想マシンを作成します。別環境にインストールする前提の方は読み飛ばしていただいても大丈夫です。今回は GPU をパススルーで利用するために作成時に設定をデフォルトから下記に変更します。ディスク容量などは都合に合わせて自由に設定してください(筆者は 200GB 分割り当てました)。
- System -> Machine
- Default (i440fx) -> q35 (PCIe パススルーで必須)
- System -> Bios
- Default (SeaBIOS) -> OVMF(UEFI)
- System -> EFI Storage
- (空白) -> リストから選択(前記事通りの設定では1つしかないはず)
仮想マシン作成後にハードウェアの追加設定を行います。
- Display: 標準 VGA
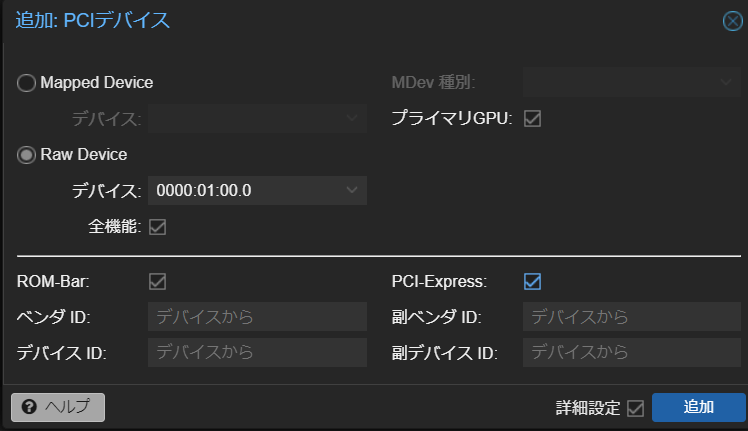
- PCI Device [下記画像参照]:
- Raw Device -> プルダウンで対象のGPUを選択
- 詳細設定 -> PCI-Express にチェック
Ubuntu サーバのインストール
まずは別マシンでインストールメディアのダウンロードしておきます。 公式: Ubuntu を入手する にアクセスすると Ubuntu Server 22.04 LTS のダウンロードリンクがあるのでこちらからダウンロードします。今回は仮想環境のため ISO のままで問題ないですが、物理マシンにインストールする人は光学メディアに焼いたり、USB メモリのインストーラを作成してください(今回は割愛します)。
次にダウンロードしたディスクを仮想サーバにマウントします。まずは仮想マシンが所属している [データセンター] -> [ノード] -> [local] -> [ISOイメージ] の順で選択し、[アップロード] をクリックするとメニューが出てくるので先ほどダウンロードしたISOを選択し、アップロードします。次に作成した仮想サーバを選択し、[Hardware] -> [CD/DVDドライブ] -> [編集] を選択するとメニューが出てくるので [CD/DVD イメージファイルを使用する] を選択して先ほどアップロードした ISO を選択、[OK] をクリックします。そして対象のマシンで [オプション] -> [ブート順] を選択、編集をクリックし先ほどの CD/DVD を一番上にもってきて [OK] を選択します。これで起動前の準備が整いました。
マシンを起動するとインストーラが起動します。日本語が選択できないため英語で進めることになると思いますが、画面の指示に従って進めていけば難しいところはないかと思います。
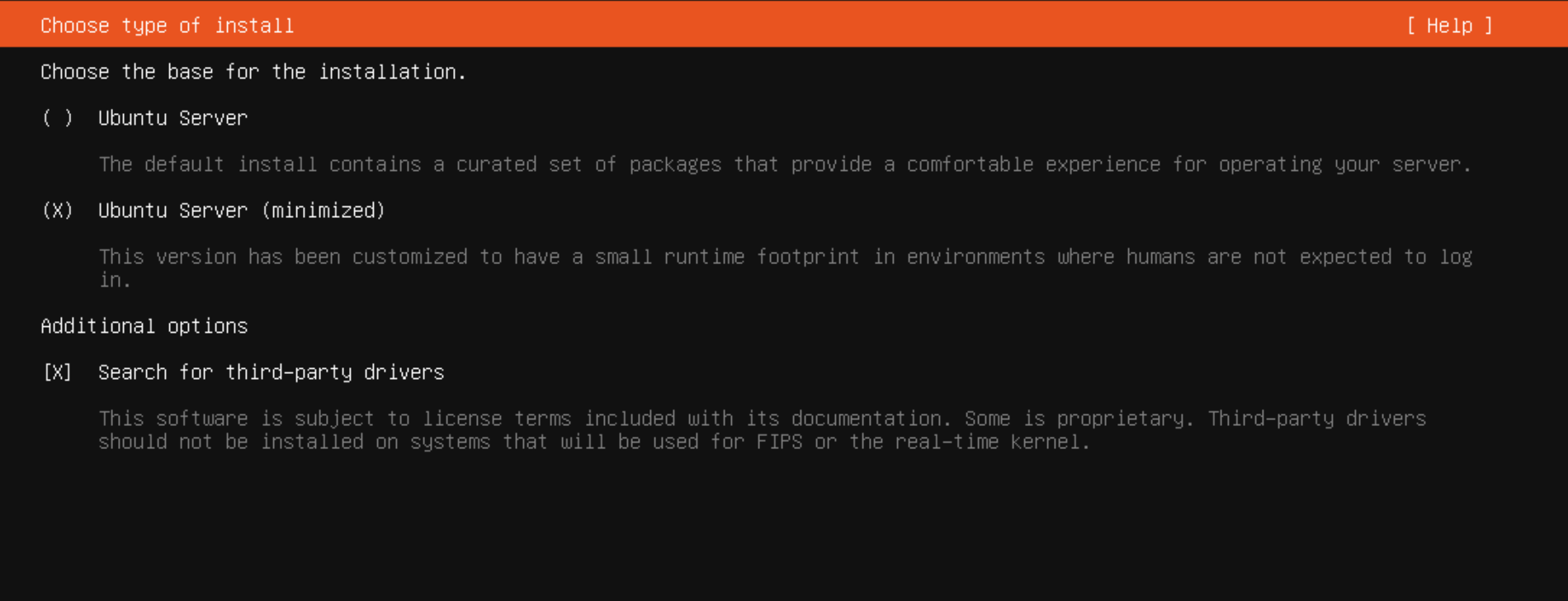
今回設定で変更したところはまず「インストール方式」の部分で、(minimized) を選択しています。必要に応じて [Search for third-party drivers] のチェックを入れてもよいですが GPU ドライバは後で手動でインストールするので PVE 環境にインストールしている人はチェックしなくてもOKです。
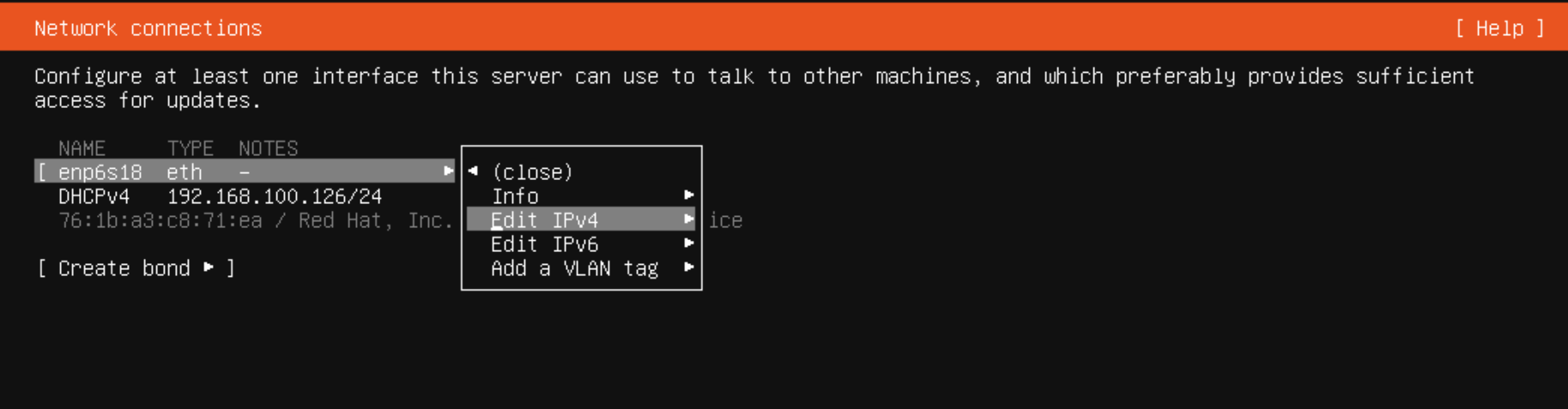
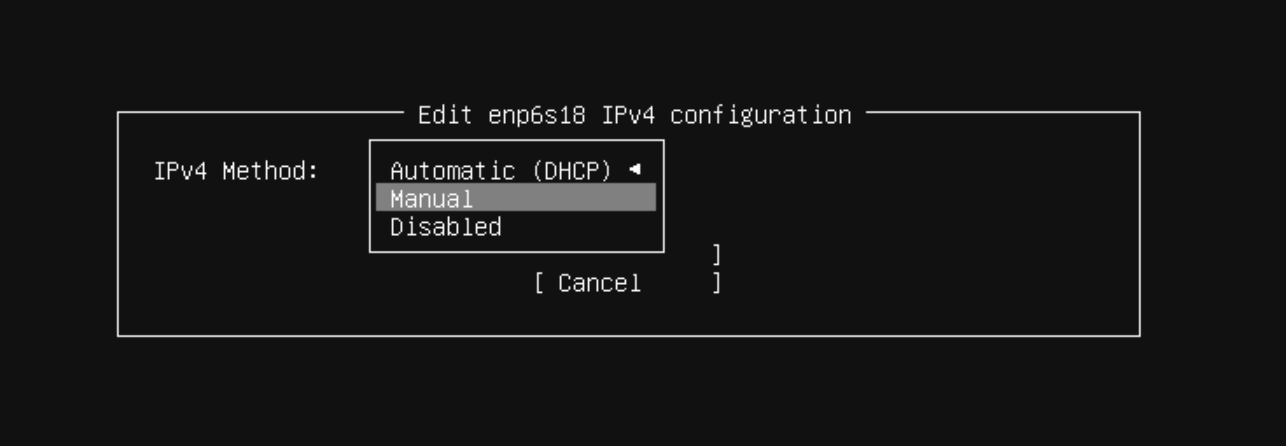
ネットワークの設定に関しては DHCP だとサーバの割り当て IP が変動する可能性があるため不便なので上記の画像のように選択し、IPv4 の設定を開き、Subnet・Address にはこのマシンに割り当てるローカル固定IPを設定、Gateway・Name servers には自宅ルータの情報を設定しました。
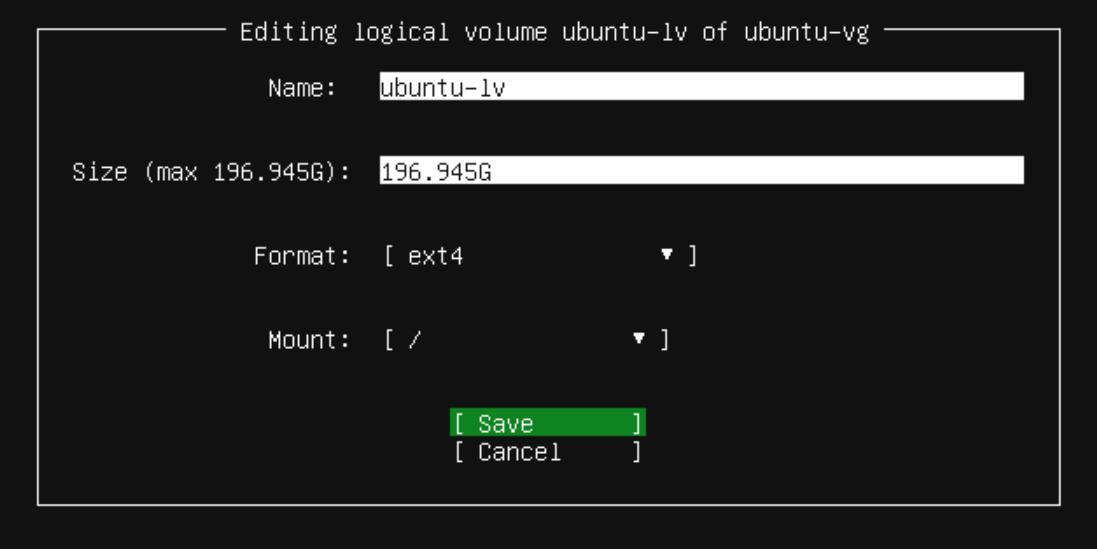
ディスクの設定についてはデフォルトだと未使用領域が残るので / に追加で割り当てました。
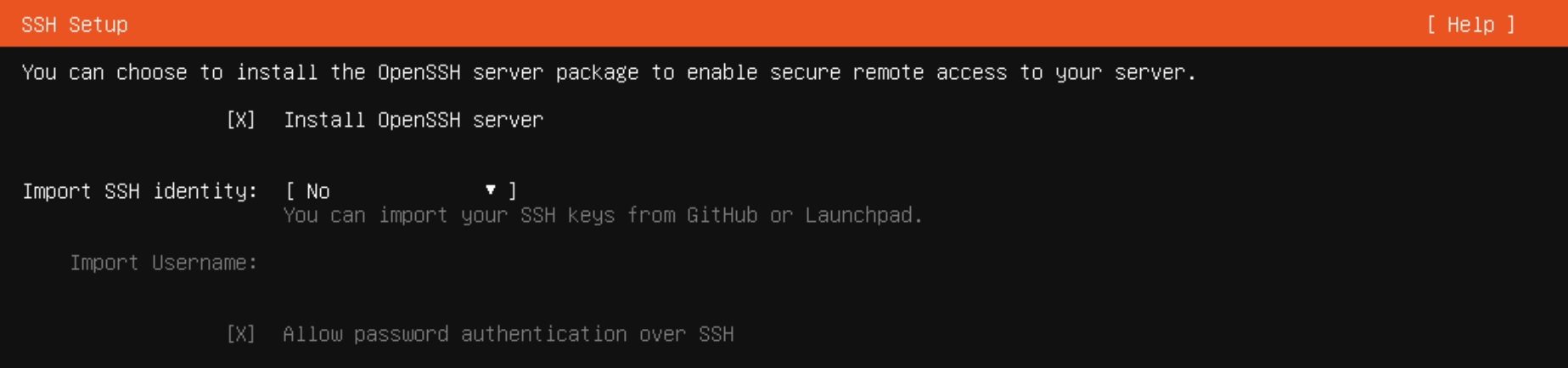
OpenSSH はインストールようにチェックボックスを ON にしておきます。
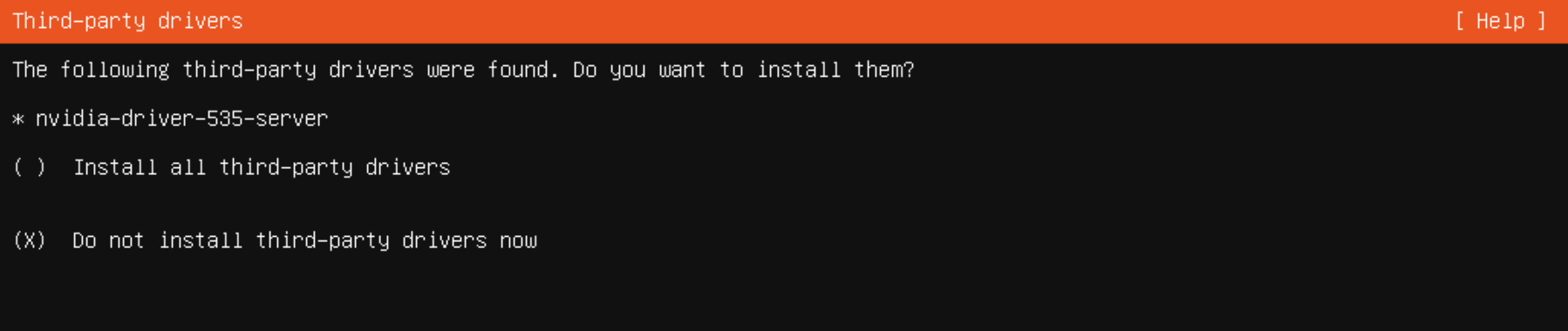
third-party ドライバのインストールについては今回 [Do not install third-party driver now] を選びます。
プロファイルの設定についてはユーザ名、サーバ名、パスワードなどについて入力します。システム管理系のコマンドについてはこのとき作成したユーザに sudo 権限が付与されるためそのままシステム管理ユーザとして利用するユーザを登録する必要がありますが個人利用の場合は分離しなくても特に問題にはならないはずです。
インストールの最終場面でインストールメディアをアンマウントするように画面に表示されるので PVE の仮想マシンの設定で [Hardware] -> [CD/DVDドライブ] -> [編集] を選択し [メディアを使用しない] を選び [OK] をクリックします。これでインストールメディアからのインストール作業が完了します。再起動後ログイン画面が表示されるはずです。
インストールに関しての詳細は下記公式リンクに詳しい解説がありますので必要に応じて参照してください。。
Ubuntu サーバの設定
ここではインストールした Ubuntu Server 環境の設定で行ったことをまとめています。。以下の作業を行いました。
- SSH 鍵の登録とパスワードログインの禁止
- 日本語関連の設定
- ほかの開発ツールのインストール
- GPU ドライバのインストール
- Docker のインストールとコンテナ作成
- Docker 本体
- NVIDIA Container Toolkit のインストール
- コンテナ作成
- 動作確認
SSH 鍵の登録とパスワードログインの禁止
SSH では公開鍵認証のみ許可し、パスワードによるログインを禁止するように設定します。ローカルのマシンで利用している SSH の公開鍵を下記コマンドでサーバに登録します。IP 部分は各自のサーバの IP を記載します。ユーザのログインパスワードを聞かれるので入力することで登録完了です。
$ ssh-copy-id [作成したユーザ名]@192.168.XXX.XXX
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/[作成したユーザ名]/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
[作成したユーザ名]@192.168.XXX.XXX's password:
下記コマンドを実行して、パスワードなしでログインできることを確認します。
$ ssh [作成したユーザ名]@192.168.XXX.XXX -i ~/.ssh/id_rsa
最後にパスワードによるログインを禁止します。
PVE のコンソールから /etc/ssh/sshd_confg を開いて下記の PasswordAuthentication 部分を検索し、no に変更し保存します。
PasswordAuthentication no
下記コマンドで ssh サービスを再起動します。
# /etc/init.d/ssh restart
日本語関連の設定
デフォルトだと言語が英語になっているため、日本語設定とロケールの設定変更を行います。下記コマンドを実行することでで日本語言語パックのインストール、ロケールの変更、フォントのインストールが完了します。
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install language-pack-ja
$ sudo update-locale LANG=ja_JP.UTF8
$ sudo apt install fontconfig
$ sudo apt install fonts-ipafont
また開発用エディタなどで利用するフォントは今回 UDEV Gothic を追加でインストールします。『UDEV Gothic は、ユニバーサルデザインフォントの BIZ UDゴシック と、 開発者向けフォントの JetBrains Mono を合成した、プログラミング向けフォントです。BIZ UDゴシックの優れた機能美はそのままに、調和的で判読性の高い英数字を提供することを目指しています。』とUDEV Gothic公式に記載がありますが、日本語コメントが混ざるソースコードが見やすくなるのでおすすめです。下記コマンドでインストールできます。
$ sudo apt install unzip
$ mkdir ~/tmp
$ cd tmp
$ wget https://github.com/yuru7/udev-gothic/releases/download/v1.3.0/UDEVGothic_v1.3.0.zip
$ unzip UDEVGothic_v1.3.0.zip
$ sudo mv UDEVGothic_v1.3.0 /usr/local/share/fonts/
$ fc-cache -fv
開発ツールのインストール
筆者はメインエディタとして Emacs を利用しているのでここでインストールしておきます。またリモートからログインして作業するのが前提なので端末のセッション管理のために tmux もあわせてインストールします。なんらかの理由でネットワーク接続が切断しても、サーバ内でセッションが維持されるため実行中のプログラムに影響を与えませんし、そのまま作業を再開することができます。利用方法については参考資料が簡潔にまとまっていまいた。
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install -y \
emacs \
emacs-mozc \
emacs-mozc-bin \
tmux \
git
tmux の設定では Emacs を利用する際に tmux 関連の操作を行うためのショートカットキー C-b が Emacs でよく使うショートカットキーとバッティングしているため、C-c に変更しているのと、端末のカラーを256色対応になるように変更しています。
set-option -g prefix C-c
unbind-key C-b
bind-key C-c send-prefix
set-option -g default-terminal screen-256color
set -g terminal-overrides 'xterm:colors=256'
Emacs の設定は今回割愛します。別記事 のローカル開発環境の構築で Emacs 関連の設定も行っているので気になる方は見てみてください。
参考: とほほのtmux入門
GPU ドライバのインストール
今回は PVE 環境を動かしているサーバに MSI GeForce RTX 3060 AERO ITX 12G OC を刺し、PCI パススルーで仮想サーバに直結する形で GPU を利用できるようにしています。ここではその GPU 用のドライバをインストールします。
まずはデフォルトで動いている Noeveau driver を停止します。/etc/modprobe.d/blacklist-nouveau.conf (なければ新規作成) に下記内容を記載します。
blacklist nouveau
options nouveau modeset=0
下記コマンドでサーバを一度再起動します。
$ sudo update-initramfs -u
$ sudo reboot
再起動後、下記コマンドを実行しインストール可能なドライバ一覧を表示します。基本は最も新しいバージョンを入れれば問題ないと思いますが、ここでは535をインストールします。
$ sudo apt update
$ sudo apt upgrade
$ ubuntu-drivers devices
modalias : pci:v000010DEd00002504sv00001462sd00008E90bc03sc00i00
vendor : NVIDIA Corporation
model : GA106 [GeForce RTX 3060 Lite Hash Rate]
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-535-server-open - distro non-free recommended
driver : nvidia-driver-525-open - distro non-free
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-535 - distro non-free
driver : nvidia-driver-525-server - distro non-free
driver : nvidia-driver-525 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
nvidia-driver-535-server-open が recommended になっていますが、今回は nvidia-driver-535 を導入します。下記コマンドを実行しドライバのインストールとマシンの再起動を行います。
$ sudo apt install -y nvidia-driver-535
$ sudo reboot
再起動完了後 nvidia-smi コマンドを実行し、GPU が正しく認識できているか確認します。下記のように表示されていればOKです。
$ nvidia-smi
Thu Jul 20 14:41:28 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 Off | 00000000:01:00.0 Off | N/A |
| 36% 39C P8 8W / 170W | 2MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
Docker のインストールとコンテナ作成
Docker に関しては別記事でも記載しましたが、オープンソースのコンテナ化技術に関するツールです。アプリケーションの実行環境の切り分けや、開発・本番環境の素早い構築ができるといったメリットがあります。これらは一般的なマシン丸ごとの仮想環境を用意できるツール (VMWare、VirtualBox、Hyper-V など) とほぼ同様のメリットですが、そのようなツールよりもオーバーヘッドが小さいため高速に起動できる、負荷もすくなく、より高いレベルでの可搬性があります。近年はサーバを仮想化技術で集約した上で、サーバ上で実行する個々のアプリケーションの環境を Docker などのコンテナ系ツールで用意するパターンも多いです。特に開発環境でメリットの大きい構成です。ここでは本環境に GPU を利用できる形で Docker をインストールします。
Docker 本体
まずは Docker のリポジトリからインストールできるように設定を行います。下記コマンドで必要なツールをインストールしておきます。
$ sudo apt install \
ca-certificates curl gnupg lsb-release
次に Docker の公式 GPG キーを追加します。
$ sudo mkdir -p /etc/apt/keyrings
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg \
| sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
下記コマンドで Docker リポジトリを登録します。
$ echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] \
https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" \
| sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
下記コマンドで Docker Engine をインストールします。
$ sudo apt update
$ sudo apt install docker-ce docker-ce-cli containerd.io
$ docker --version
Docker version 24.0.4, build 3713ee1
$ docker compose version
Docker Compose version v2.19.1
ここで一度動作確認を行っておきます。下記のように表示されればOKです。
$ sudo docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
719385e32844: Pull complete
Digest: sha256:926fac19d22aa2d60f1a276b66a20eb765fbeea2db5dbdaafeb456ad8ce81598
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
そのままだと sudo なしで実行できないので、管理者権限なしで実行できるように設定します。
$ sudo usermod -aG docker $USER
$ su - ${USER}
下記コマンドで管理者権なしで実行できることを確認します。
$ docker run hello-world
Hello from Docker!
...
NVIDIA Container Toolkit のインストール
下記コマンドで GPG キーのダウンロードとリポジトリの追加を行います。
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
下記コマンドでリポジトリから nvidia-container-toolkit をインストールし、設定を行ったのち、Docker デーモンを再起動します。
$ sudo apt-get update
$ sudo apt-get install -y nvidia-container-toolkit
$ sudo nvidia-ctk runtime configure --runtime=docker
INFO[0000] Loading docker config from /etc/docker/daemon.json
INFO[0000] Config file does not exist, creating new one
INFO[0000] Wrote updated config to /etc/docker/daemon.json
INFO[0000] It is recommended that the docker daemon be restarted.
$ sudo systemctl restart docker
下記コマンドで NVIDA 公式 Docker イメージを利用し、コンテナ内で nvidia-smi コマンドを実行した場合の結果を確認します。下記のように表示されればOKです。
$ docker run --rm --runtime=nvidia --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
Unable to find image 'nvidia/cuda:12.2.0-base-ubuntu22.04' locally
12.2.0-base-ubuntu22.04: Pulling from nvidia/cuda
6b851dcae6ca: Already exists
8f5f0e71700a: Already exists
fac7ce4a13c3: Already exists
1af9bee222cb: Already exists
d47e0a26d15c: Already exists
Digest: sha256:f8870283bea6a85ba4b4a5e1b65158dd15e8009e433539e7c83c94707e703a1b
Status: Downloaded newer image for nvidia/cuda:12.2.0-base-ubuntu22.04
Mon Jul 24 05:48:04 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 Off | 00000000:01:00.0 Off | N/A |
| 36% 35C P8 13W / 170W | 191MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
コンテナ作成
ここでは下記ツールを一式インストールしたコンテナを作成します。
- ソースコード管理: Git
- ダウンロード: wget
- アーカイブ関連: zip, unzip
- C, C++ ビルド関連: cmake, build-essential, libboost 系
- 線形代数演算: BLAS, LAPACK
- Python 関連
- Python本体: Python 3.9 + pip
- 開発環境: Jupyter Lab
- データ分析: scikit-learn, Numpy, Scipy, Pandas
- データモデリング: XGBoost, LightGBM, CatBoost
- AutoML: PyCaret
- データ可視化: Graphviz, Matplotlib, Japanize Matplotlib, Seaborn
- DeepLearning: PyTorch
- 進行状況管理: tqdm
- ONNX関連: skl2onnx, onnxmltools, onnxruntime-gpu
- 画像処理関連: OpenCV, Pillow
- AWS関連: Boto3
コンテナ用のルートディレクトリを(~/ 以下などの)適当な場所に作成、Dockerfile と docker-compose.yml を下記のような形で作成します。
FROM nvidia/cuda:12.2.0-base-ubuntu22.04
RUN apt-get update && apt-get -y upgrade && \
apt-get install -y locales && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && \
echo $TZ > /etc/timezone
RUN apt-get install -y software-properties-common && \
add-apt-repository ppa:deadsnakes/ppa && \
apt-cache policy python3.9
RUN apt-get install -y \
git \
wget \
zip \
unzip \
cmake \
build-essential \
libboost-dev \
libboost-system-dev \
libboost-filesystem-dev \
libblas-dev \
liblapack-dev \
python3.9 \
python3.9-dev \
python3-pip \
python-is-python3 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --upgrade setuptools && \
pip install --no-cache-dir \
'pycaret[full]>=3.0.4' && \
pip install --no-cache-dir \
scikit-learn \
numpy \
scipy \
pandas && \
pip install --no-cache-dir \
jupyterlab \
ipywidgets \
plotly \
graphviz \
shap \
matplotlib \
japanize_matplotlib \
seaborn \
tqdm && \
pip install --no-cache-dir \
lightgbm \
xgboost \
catboost && \
pip install --no-cache-dir \
torch \
torchvision \
torchaudio && \
pip install --no-cache-dir \
skl2onnx \
onnxmltools \
onnxruntime-gpu && \
pip install --no-cache-dir \
pillow \
opencv-python && \
pip install --no-cache-dir \
boto3
version: '12.2'
services:
python3:
restart: no
build: .
container_name: 'pytorch-base'
working_dir: '/root/'
tty: true
command:
jupyter-lab --ip=0.0.0.0 --allow-root --ServerApp.open_browser=False
ports:
- "8888:8888"
volumes:
- ./opt:/root/opt
- ./root_jupyter:/root/.jupyter
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
environment:
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=all
Dockerfile については pip のインストール部分で確認を行いながら作成した関係で pip コマンドがツールの分類ごとに小分けになっていますがそのまま残しています。言語の設定、パッケージのキャッシュ削除なども対応しました。
docker-compse.yml については下記の deploy: と environment: に記載した内容が GPU のための設定です。
動作確認
下記コマンドでコンテナを作成し起動します。
$ docker compose create
$ docker compose start
$ docker ps
...
ここでCONTAINER ID を控えておき下記コマンドを実行すると、Jupyter Lab アクセス用の token が確認できます。
$ docker logs [CONTAINER ID]
...
http://(e22198a8202b or 127.0.0.1):8888/?token=xxxxxxxxx
ローカル環境のブラウザから http://[ubuntu server IP]:8888/?token=xxxxxxxxx にアクセスし、Jupyter Lab が起動していて、notebook が作成できることを確認します。作成した notebook に以下の PyCaret、PyTorch 動作確認用のコードを記載し動作することを確認する。
PyCaret 確認
import pycaret
pycaret.__version__
'3.0.4'
# loading sample dataset from pycaret dataset module
from pycaret.datasets import get_data
data = get_data('diabetes')
| Number... | Plasma... | Diastolic... | Triceps... | 2-Hour... | Body... | Diabetes... | Age... | Class... | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.228 | 33 | 1 |
# import pycaret classification and init setup
from pycaret.classification import *
s = setup(data, target = 'Class variable', session_id = 123)
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Target | Class variable |
| 2 | Target type | Binary |
| 3 | Original data shape | (768, 9) |
| 4 | Transformed data shape | (768, 9) |
| 5 | Transformed train set shape | (537, 9) |
| 6 | Transformed test set shape | (231, 9) |
| 7 | Numeric features | 8 |
| 8 | Preprocess | True |
| 9 | Imputation type | simple |
| 10 | Numeric imputation | mean |
| 11 | Categorical imputation | mode |
| 12 | Fold Generator | StratifiedKFold |
| 13 | Fold Number | 10 |
| 14 | CPU Jobs | -1 |
| 15 | Use GPU | False |
| 16 | Log Experiment | False |
| 17 | Experiment Name | clf-default-name |
| 18 | USI | d02c |
# import ClassificationExperiment and init the class
from pycaret.classification import ClassificationExperiment
exp = ClassificationExperiment()
# check the type of exp
type(exp)
pycaret.classification.oop.ClassificationExperiment
# init setup on exp
exp.setup(data, target = 'Class variable', session_id = 123)
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Target | Class variable |
| 2 | Target type | Binary |
| 3 | Original data shape | (768, 9) |
| 4 | Transformed data shape | (768, 9) |
| 5 | Transformed train set shape | (537, 9) |
| 6 | Transformed test set shape | (231, 9) |
| 7 | Numeric features | 8 |
| 8 | Preprocess | True |
| 9 | Imputation type | simple |
| 10 | Numeric imputation | mean |
| 11 | Categorical imputation | mode |
| 12 | Fold Generator | StratifiedKFold |
| 13 | Fold Number | 10 |
| 14 | CPU Jobs | -1 |
| 15 | Use GPU | False |
| 16 | Log Experiment | False |
| 17 | Experiment Name | clf-default-name |
| 18 | USI | a007 |
<pycaret.classification.oop.ClassificationExperiment at 0x7f0599abef80>
# compare baseline models
best = compare_models()
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (Sec) | |
|---|---|---|---|---|---|---|---|---|---|
| lr | Logistic Regression | 0.7689 | 0.8047 | 0.5602 | 0.7208 | 0.6279 | 0.4641 | 0.4736 | 0.1690 |
| ridge | Ridge Classifier | 0.7670 | 0.0000 | 0.5497 | 0.7235 | 0.6221 | 0.4581 | 0.4690 | 0.0100 |
| ld | Linear Discriminant Analysis | 0.7670 | 0.8055 | 0.5550 | 0.7202 | 0.6243 | 0.4594 | 0.4695 | 0.0130 |
| rf | Random Forest Classifier | 0.7485 | 0.7911 | 0.5284 | 0.6811 | 0.5924 | 0.4150 | 0.4238 | 0.1150 |
| nb | Naive Bayes | 0.7427 | 0.7955 | 0.5702 | 0.6543 | 0.6043 | 0.4156 | 0.4215 | 0.0120 |
| catboost | CatBoost Classifier | 0.7410 | 0.7993 | 0.5278 | 0.6630 | 0.5851 | 0.4005 | 0.4078 | 0.5480 |
| gbc | Gradient Boosting Classifier | 0.7373 | 0.7917 | 0.5550 | 0.6445 | 0.5931 | 0.4013 | 0.4059 | 0.0510 |
| ada | Ada Boost Classifier | 0.7372 | 0.7799 | 0.5275 | 0.6585 | 0.5796 | 0.3926 | 0.4017 | 0.0390 |
| et | Extra Trees Classifier | 0.7299 | 0.7788 | 0.4965 | 0.6516 | 0.5596 | 0.3706 | 0.3802 | 0.0950 |
| qda | Quadratic Discriminant Analysis | 0.7282 | 0.7894 | 0.5281 | 0.6558 | 0.5736 | 0.3785 | 0.3910 | 0.0130 |
| lightgbm | Light Gradient Boosting Machine | 0.7133 | 0.7645 | 0.5398 | 0.6036 | 0.5650 | 0.3534 | 0.3580 | 14.9770 |
| knn | K Neighbors Classifier | 0.7001 | 0.7164 | 0.5020 | 0.5982 | 0.5413 | 0.3209 | 0.3271 | 0.0220 |
| dt | Decision Tree Classifier | 0.6928 | 0.6512 | 0.5137 | 0.5636 | 0.5328 | 0.3070 | 0.3098 | 0.0140 |
| xgboost | Extreme Gradient Boosting | 0.6853 | 0.7516 | 0.4912 | 0.5620 | 0.5216 | 0.2887 | 0.2922 | 0.0300 |
| dummy | Dummy Classifier | 0.6518 | 0.5000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0130 |
| svm | SVM - Linear Kernel | 0.5954 | 0.0000 | 0.3395 | 0.4090 | 0.2671 | 0.0720 | 0.0912 | 0.0110 |
# compare models using OOP
exp.compare_models()
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (Sec) | |
|---|---|---|---|---|---|---|---|---|---|
| lr | Logistic Regression | 0.7689 | 0.8047 | 0.5602 | 0.7208 | 0.6279 | 0.4641 | 0.4736 | 0.0170 |
| ridge | Ridge Classifier | 0.7670 | 0.0000 | 0.5497 | 0.7235 | 0.6221 | 0.4581 | 0.4690 | 0.0110 |
| lda | Linear Discriminant Analysis | 0.7670 | 0.8055 | 0.5550 | 0.7202 | 0.6243 | 0.4594 | 0.4695 | 0.0140 |
| rf | Random Forest Classifier | 0.7485 | 0.7911 | 0.5284 | 0.6811 | 0.5924 | 0.4150 | 0.4238 | 0.0520 |
| nb | Naive Bayes | 0.7427 | 0.7955 | 0.5702 | 0.6543 | 0.6043 | 0.4156 | 0.4215 | 0.0130 |
| catboost | CatBoost Classifier | 0.7410 | 0.7993 | 0.5278 | 0.6630 | 0.5851 | 0.4005 | 0.4078 | 0.0180 |
| gbc | Gradient Boosting Classifier | 0.7373 | 0.7917 | 0.5550 | 0.6445 | 0.5931 | 0.4013 | 0.4059 | 0.0510 |
| ada | Ada Boost Classifier | 0.7372 | 0.7799 | 0.5275 | 0.6585 | 0.5796 | 0.3926 | 0.4017 | 0.0390 |
| et | Extra Trees Classifier | 0.7299 | 0.7788 | 0.4965 | 0.6516 | 0.5596 | 0.3706 | 0.3802 | 0.0700 |
| qda | Quadratic Discriminant Analysis | 0.7282 | 0.7894 | 0.5281 | 0.6558 | 0.5736 | 0.3785 | 0.3910 | 0.0130 |
| lightgbm | Light Gradient Boosting Machine | 0.7133 | 0.7645 | 0.5398 | 0.6036 | 0.5650 | 0.3534 | 0.3580 | 0.0640 |
| knn | K Neighbors Classifier | 0.7001 | 0.7164 | 0.5020 | 0.5982 | 0.5413 | 0.3209 | 0.3271 | 0.0230 |
| dt | Decision Tree Classifier | 0.6928 | 0.6512 | 0.5137 | 0.5636 | 0.5328 | 0.3070 | 0.3098 | 0.0140 |
| xgboost | Extreme Gradient Boosting | 0.6853 | 0.7516 | 0.4912 | 0.5620 | 0.5216 | 0.2887 | 0.2922 | 0.0290 |
| dummy | Dummy Classifier | 0.6518 | 0.5000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0130 |
| svm | SVM - Linear Kernel | 0.5954 | 0.0000 | 0.3395 | 0.4090 | 0.2671 | 0.0720 | 0.0912 | 0.0110 |
LogisticRegression LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=1000, multi_class='auto', n_jobs=None, penalty='l2', random_state=123, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False)
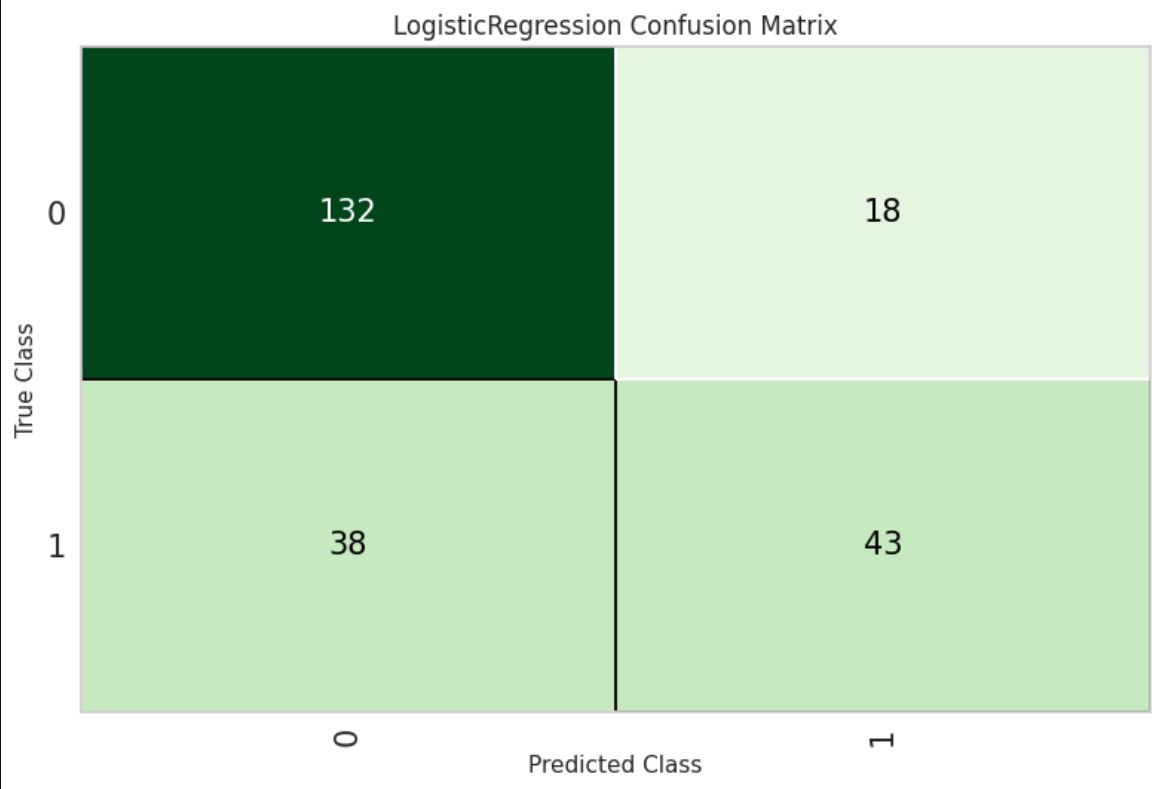
# plot confusion matrix
plot_model(best, plot = 'confusion_matrix')
PyTorch 確認
!nvidia-smi
Mon Jul 24 22:12:15 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 Off | 00000000:01:00.0 Off | N/A |
| 37% 35C P8 13W / 170W | 5MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
# https://water2litter.net/rum/post/pytorch_tutorial_classifier_gpu/
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# ニューラルネットワークの定義
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# データセット読み込み
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# ネットワークのインスタンス作成
net = Net()
# 損失関数とオプティマイザーの定義
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Files already downloaded and verified
Files already downloaded and verified
# GPUを使用する
device_str = "cuda:0" if torch.cuda.is_available() else "cpu"
device = torch.device(device_str)
net.to(device) # モデルの転送
# 学習ループ
for epoch in range(2): # 総データに対する学習回数
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# データをリストに格納
inputs, labels = data[0].to(device), data[1].to(device) # データの転送
# パラメータを0にリセット
optimizer.zero_grad()
# 順方向の計算、損失計算、バックプロパゲーション、パラメータ更新
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 計算状態の出力
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 計算結果のモデルを保存
torch.save(net.state_dict(), './cifar_net.pth')
[1, 2000] loss: 2.177 [1, 4000] loss: 1.923 [1, 6000] loss: 1.743 [1, 8000] loss: 1.596 [1, 10000] loss: 1.513 [1, 12000] loss: 1.463 [2, 2000] loss: 1.404 [2, 4000] loss: 1.369 [2, 6000] loss: 1.351 [2, 8000] loss: 1.341 [2, 10000] loss: 1.307 [2, 12000] loss: 1.301 Finished Training
ここまでで PyCaret と PyTorch (GPU利用) が無事動作しているのが確認できました。
おわりに
データ分析・AI関連でインフラ周りの準備は一苦労することになりますが、1度ベースとなる構築方法を覚えてしまえば、あとはどこかが多少変わる程度なので、ここに内容が一通り理解できていれば環境構築で大きく困ることはないはずです。今回は PyTorch を利用していますが、TensorFlow の場合インストールするライブラリが多少変わるだけですし、GPU 周りのドライバや分析に利用するライブラリを更新する場合は Dockerfile を差分管理しておけばすぐに切り戻すことも可能です。今後はこの環境で行った分析やライブラリの利用法などもまとめていきたいと考えています。